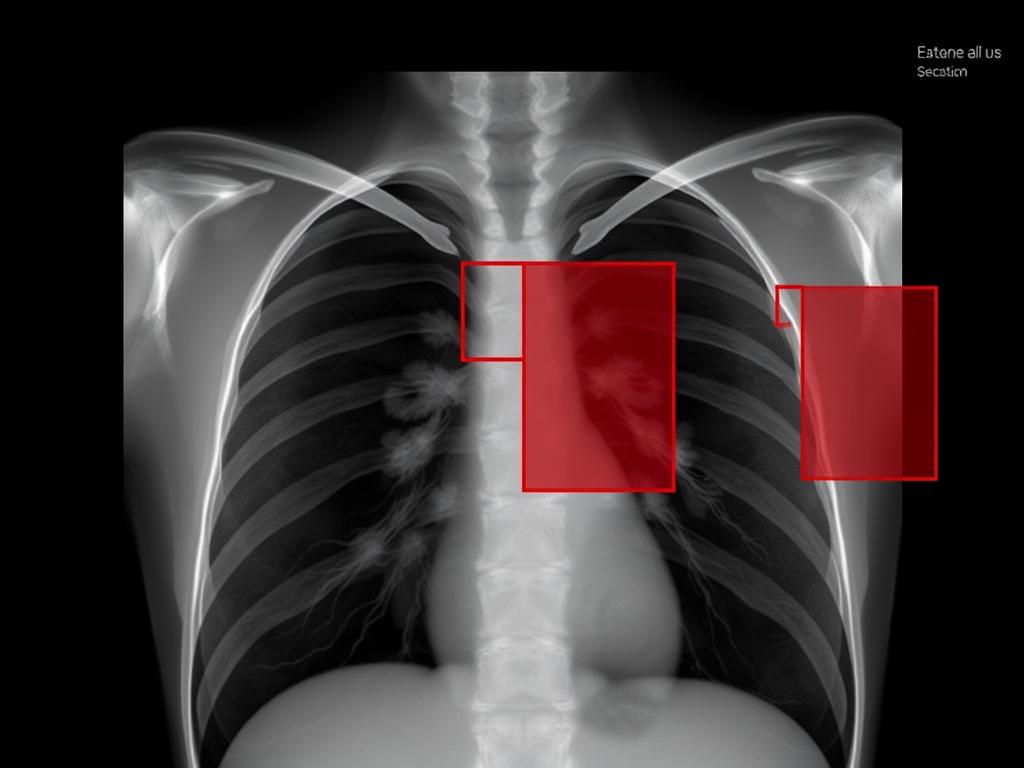
The Triple Attention U-Net Is A Powerful Extension Of The Traditional U-Net Used Here To Segment Lung
The Triple Attention U-Net is a powerful extension of the traditional U-Net, used here to segment lung regions from chest X-ray (CXR) images. The segmentation improves the classification model by focusing only on the relevant lung area, eliminating background noise like ribs and spine. It combines three attention mechanisms: 1. Pixel Attention – focuses on important pixel-wise details. 2. Spatial Attention – highlights “where” in the spatial layout to focus. 3. Channel (SE) Attention – emphasizes “what” feature channels are important. The Triple Attention Improvised U-Net is an enhanced variant of the conventional U-Net architecture, specifically designed for accurate segmentation of lung regions in chest X-ray (CXR) images. By isolating the lung areas, the model effectively reduces background noise from irrelevant structures such as the ribs and spine, thereby enhancing the performance of downstream classification tasks. This architecture integrates three complementary attention mechanisms—Pixel Attention, Channel Attention, and Spatial Attention—which enable the network to selectively emphasize important features and regions. As a result, the model achieves improved localization accuracy and precise boundary delineation, making it highly effective for medical image segmentation applications. It combines three attention mechanisms: 1. Encoder–Decoder Architecture: The model retains the fundamental U-Net structure consisting of an encoder path that captures context and a decoder path that enables precise localization. Skip connections are used to transfer high-resolution features from encoder to decoder layers, preserving spatial detail. 2. Pixel Attention Module (PA): Integrated at the bottleneck, the Pixel Attention module refines feature maps by assigning attention weights at the pixel level. This allows the model to emphasize fine-grained structural details and suppress background noise, which is essential for segmenting small or subtle anomalies. 3. Channel Attention Module (CA): The Channel Attention module is embedded after key convolutional blocks in both the encoder and decoder. It adaptively recalibrates the importance of each feature channel by learning inter-channel dependencies using mechanisms such as Squeeze-and-Excitation (SE) or Efficient Channel Attention (ECA). This guides the network to prioritize informative feature maps that carry meaningful semantics. 4. Spatial Attention Module (SA): To improve spatial sensitivity, Spatial Attention is applied after skip connections. It utilizes average and max pooling operations along the channel axis to create an attention map that identifies the most relevant spatial locations. This enhances the model’s ability to focus on clinically significant regions, such as lesions or infected lung areas. By combining pixel-wise detail enhancement, channel-wise feature selection, and spatially-aware localization, the Triple Attention Improved U-Net significantly boosts segmentation performance in terms of accuracy, boundary precision, and generalization. Improvised U-Net for Medical Image Segmentation The Improvised U-Net model is a modified version of the traditional U-Net architecture, designed for efficient and accurate segmentation of medical images such as chest X-rays. The model follows the classic encoder–decoder structure with skip connections, but with refined architectural adjustments that improve feature representation and reconstruction capability. 1. Encoder Path: The encoder captures hierarchical features through a series of convolutional and max pooling layers: • Each block in the encoder consists of a 2D convolutional layer followed by a max pooling layer. • Feature depth increases progressively (64 → 128 → 256), allowing the model to learn low- to high-level spatial patterns. 2. Bottleneck: At the deepest layer of the network, the bottleneck consists of a convolutional block with 512 filters. This layer captures rich, abstract representations that integrate global context and structural details. 3. Decoder Path: The decoder reconstructs the spatial resolution using transposed convolutional layers followed by feature concatenation and convolution: Skip connections merge encoder features with decoder layers to preserve spatial context. • Transposed convolutions (also known as deconvolutions) help in up sampling the feature maps. • Decoder feature depth decreases symmetrically (256 → 128 → 64), matching the encoder’s structure.
02.07.2025 17:49